Ich bin gestern Abend beim Dortmunder Business Intelligence & Analytics Meetup auf Data Vault 2.0 aufmerksam geworden. Es handelt sich hierbei um ein Paket aus Modellierungs-, Architektur- und Methodologieansätzen. Der Modellierungsansatz fürs DWH, zeichnet sich durch eine hohe Flexibilität bei Änderungen, eine vollständige Historisierung und starke Parallelisierung der Ladeprozesse aus.
In diesem Beitrag möchte ich meine aktuellen Erkenntnisse zusammenfassen.
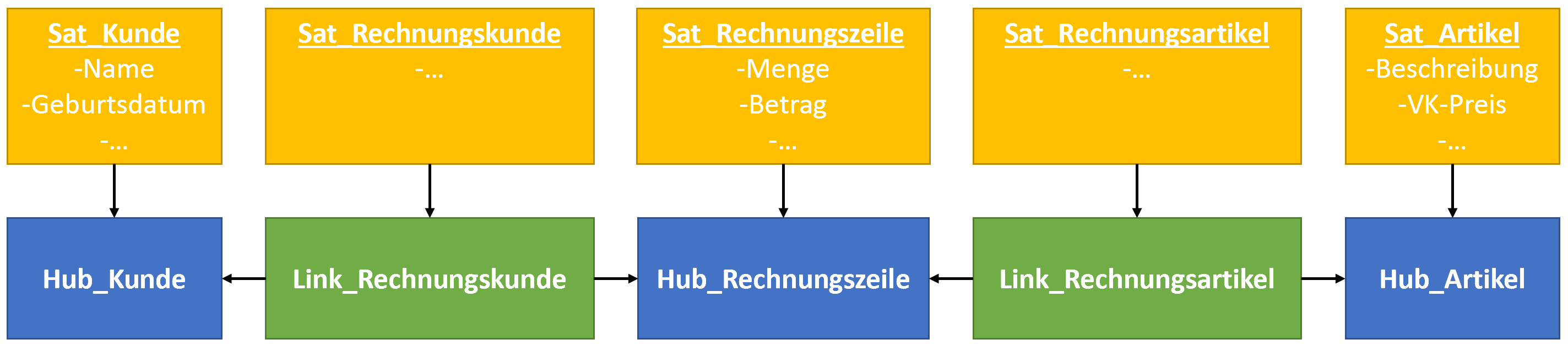
Bei der Data Vault Modellierung werden die Informationen in drei Kategorien eingeteilt und in entsprechenden Datenbanktabellen gespeichert. Es handelt sich hierbei um die folgende Kategorien:
Hub
Ein Hub ist eine Liste von eindeutigen Geschäftsschlüssen, die eine Geschäftsobjekt identifiziert. (z.B. Kundennummer bei Kunden, Rechnungsnummer bei Rechnungen, Artikelnummer bei Artikel)
Link
Ein Link verbindet Geschäftsobjekte (Hubs) miteinander und bildet somit die Beziehung zwischen den Informationen ab. (z.B. Rechnungsnummer zu einer Kundennummer)
Satellit
Ein Satellit ist eine Liste von Attributen, die ein Geschäftsobjekt (Hub) oder Beziehung (Link) beschreiben. (z.B. Name, Geburtsdatum oder Geschlecht eines Kunden / einer Kundennummer)
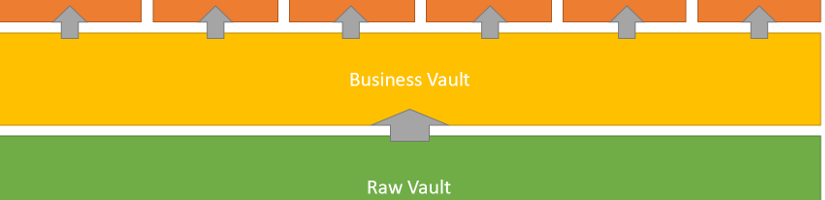
Durch diese Art der Modellierung, müssen bei Änderung in der Regel keine bestehenden Tabellen angepasst werden, sondern es werden einfach neue Tabellen (z.B. zusätzliche Satelliten) hinzugefügt.
In den Satelliten findet auch die Historisierung statt. Durch einen „INSERT-Only“ Ladeprozess werden immer nur zusätzliche Daten im Data Vault gespeichert.
Dieser Ladeprozess unterstützt auch die starke Parallelisierung. Zusätzlich werden Lookups in der Datenbank vermieden und z.B. der Surrogate Key für die Verknüpfung der Tabellen per Hash-Methode ermittelt.
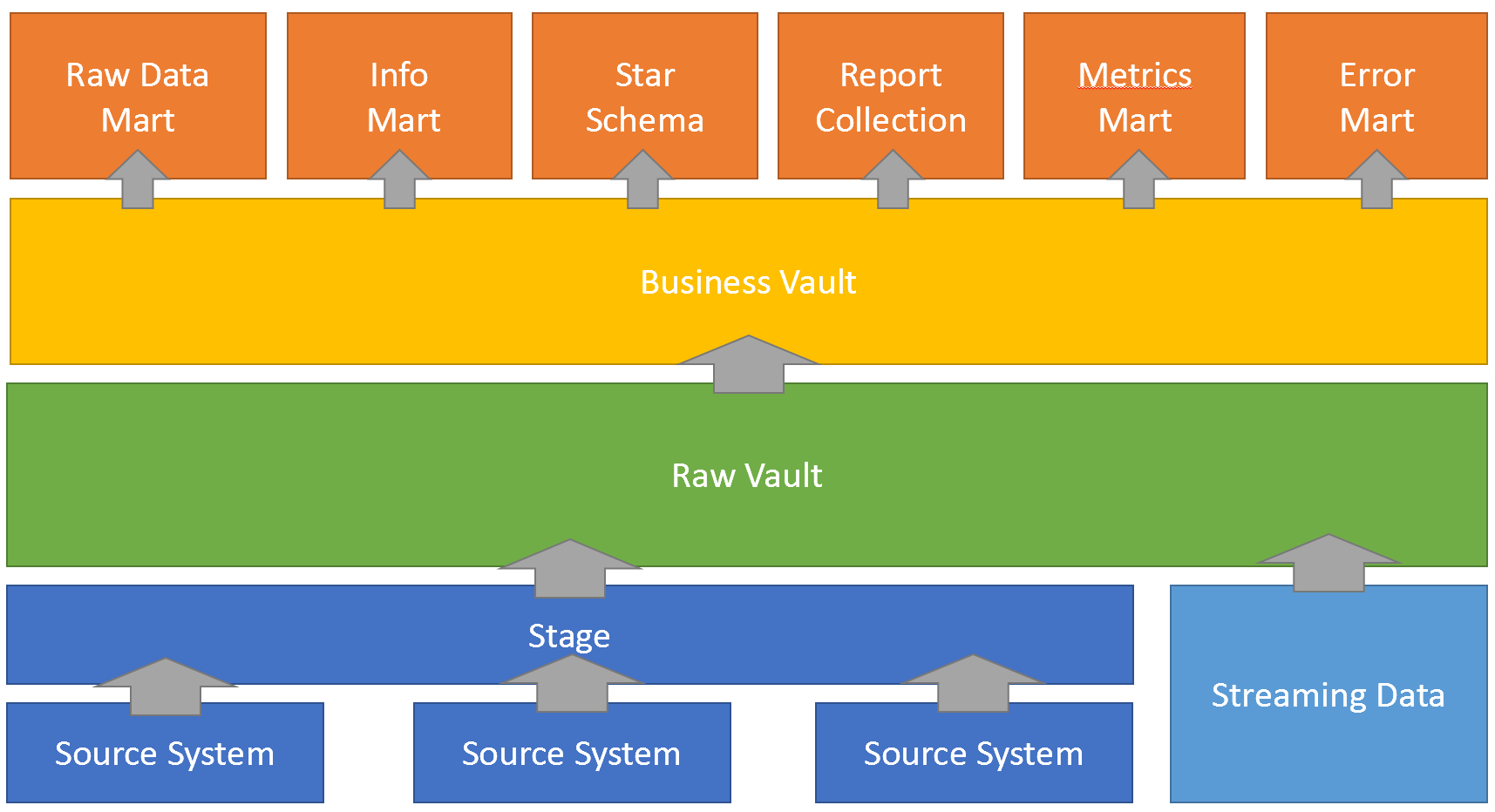
Die Architektur besteht aus den folgenden Schritten:
- Kopieren der Daten aus verschiedenen Quellsystemen in den Stage-Bereich
- Beladung des Raw Vault, der 100% der Quelldaten enthält. Streaming Daten können optional direkt im Raw Vault gespeichert werden.
- Danach wird der Business Vault aufgebaut, in dem die Geschäftsregeln angewendet werden. Daten werden bereinigt, fehlerhafte Datensätze werden erkannt usw. Dies bedeutet, dass der Business Vault nicht unbedingt 100% der Daten enthält.
- Der Business Vault dient als Quelle für:
- Raw Data Mart (enthält 100% der Daten, auch die fehlerhaften)
- Info Mart
- Star Schema
- Berichte
- Metrics Mart (enthält Informationen zum Ausführungsverlauf, etc.)
- Fehler Mart (enthält fehlerhafte Daten, z.B. für die Verantwortlichen der Datenqualität)
Quellen:
Als weitere Quelle findet Ihr hier den „Data Vault Modeling Guide“ von Hans Hultgren
https://hanshultgren.files.wordpress.com/2011/05/data_vault_modeling_guide_2016_v2.pdf
Good Article